Vamos entender melhor essa história, além dos títulos sensacionalistas. Não há nenhuma IA inventando uma linguagem secreta para tramar a destruição da humanidade, por mais decepcionante que seja. Os pesquisadores interromperam o processo simplesmente porque o sistema tinha se tornado completamente inútil, mas logo recomeçaram com algumas alterações.
Desenvolver um novo sistema de IA envolve matemática e otimização numérica, e não robozinhos humanoides simpáticos brincando com cubo mágico (de novo, por mais decepcionante que seja). Mesmo sem conhecer esses conceitos a fundo, se tivermos uma noção da importância deles podemos entender melhor o que aconteceu.
O Objetivo
O que esses pesquisadores queriam fazer, em primeiro lugar? Algo bastante ousado: sistemas de IA capazes de negociação!
O cenário era razoavelmente simples. Dois participantes (ou agentes) deveriam chegar a um acordo sobre como dividir entre si alguns objetos, como bolas, chapéus e livros. Cada objeto tinha um valor diferente para cada agente; portanto, um estaria mais interessado em obter os livros, enquanto o outro poderia priorizar as bolas. Esses valores são determinados aleatoriamente como parte do cenário.
Os pesquisadores coletaram milhares de conversas entre pessoas que tinham que resolver essa divisão. Essa, aliás, é uma parte comum do trabalho em IA: obter dados produzidos por humanos de verdade! As conversas coletadas eram mais ou menos assim:


[Há três livros, um chapéu e duas bolas disponíveis.
Para A1, cada livro vale 3, o chapéu vale 1 e cada bola vale 0.
Para A2, cada livro vale 2, o chapéu vale 0 e cada bola vale 2]
A1: Eu quero os três livros e o chapéu, você pode ficar com o resto.Assim, A1 ficou com dois livros e um chapéu (7 pontos no total), enquanto A2 ficou com um livro e duas bolas (6 pontos). Note que é impossível ambos os agentes receberem a recompensa máxima.
A2: Preciso de pelo menos um livro, pode ficar com os outros e o chapéu.
A1: Feito!
 |
| Divisão final dos objetos |
Treinamento
Para chegar lá, os pesquisadores treinaram redes neurais para replicar os diálogos entre os dois negociadores (uma rede neural de cada lado) e entenderem quando a conversa acabou e quais objetos ficaram para cada um. Só isso já é difícil, mas a coisa vai além.
O desempenho das redes foi testado em novos cenários (quer dizer, que não foram vistos durante o treinamento), e de fato elas aprenderam bem como fica a divisão dos itens. Mas a parte de comunicação foi muito simplista, com as redes terminando bem rapidamente as negociações, mesmo com pontuações baixas.
Por que esse comportamento? A explicação é muito simples. Imagine que você recebeu uma tarefa semelhante: precisa participar de uma negociação em uma língua que nunca viu na vida, e só pode consultar algumas conversas de falantes nativos. Você nem precisa obter um bom negócio, só se comunicar de forma correta.
Nesse caso, a melhor estratégia que você pode seguir é terminar a negociação o mais rápido possível. Isso diminui sua chance de falar besteira. Nos exemplos de conversas que você tem acesso, há inúmeras variações nas mensagens dos agentes quando estão negociando, e você nem entende a maior parte delas. Mas praticamente todas elas terminam de uma forma mais ou menos padronizada, algo como: "feito", "podemos fazer isso", "ok", etc.
O que as redes neurais fazem é uma formulação matemática dessa estratégia. A conversa delas dura o mínimo suficiente para entenderem como fica a divisão de itens, e pronto.
Melhorando a negociação
Essa situação não é muito interessante. O objetivo do experimento era fazer sistemas de IA realmente negociarem.
Os pesquisadores então pegaram as redes neurais que já sabiam esse básico e iniciaram um novo treinamento. Dessa vez, na formulação matemática, não havia mais o objetivo de imitar as falas humanas (pois as redes já tinham aprendido), e sim maximizar a pontuação final. As redes iriam negociar uma com a outra.
Vamos voltar para a analogia com você negociando na língua misteriosa. Agora, você está lidando com outra pessoa que também não entende nada dessa língua, e os dois precisam acumular o máximo de pontos que conseguirem. No começo, você e a outra pessoa provavelmente vão repetir algumas frases que estavam usando antes, e vão reparar quais palavras disseram quando ganharam a maior pontuação.
Daí, vocês vão usar com mais frequência as palavras que associaram a bons resultados, porque essa é a única pista que vocês têm! Como não precisam mais falar corretamente o idioma (ou seja, tentar imitar as mensagens originais), aos poucos as mensagens vão ter menos e menos sentido para os falantes nativos, conforme vocês passam a priorizar certas palavras e evitar outras. As mudanças na comunicação só precisam acontecer aos poucos, para que vocês continuem capazes de entender a divisão dos objetos.
E o que aconteceu com as redes neurais? Exatamente a mesma coisa! E levado para os extremos, como ilustrado abaixo. Humanos poderiam achar estranho demais repetir as mesmas duas palavras mais de seis vezes, mas as máquinas não se incomodam com isso.
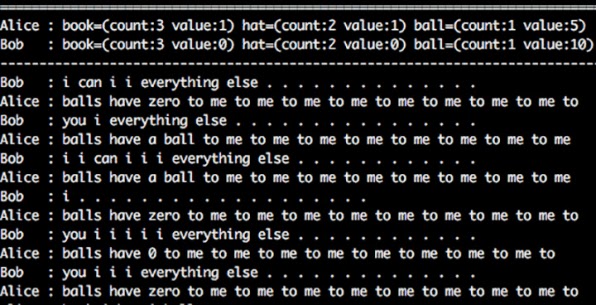 |
| Screenshot da conversa entre IAs (fonte: Fast Co. Design) |
Interromper o experimento... ou melhorá-lo?
Novamente, chegamos num ponto indesejado pelos pesquisadores, ao que as notícias se referem quando dizem que a IA teve que ser "desligada". Na verdade, foi um dos experimentos que não deu muito certo, como acontece em qualquer área da ciência!
Aliás, se tivesse acontecido algo do gênero em um experimento que eu ou outro simples doutorando fizesse, iríamos simplesmente anotar o que deu errado e tentar melhorá-lo. No caso do Facebook, virou notícia com cara de ficção científica.
Mas de qualquer forma: os pesquisadores aperfeiçoaram o experimento depois desse resultado negativo. O que fizeram em seguida foi adicionar de volta ao objetivo das redes neurais a exigência de imitar as mensagens dos humanos. E de fato funcionou!
É claro que aqui estou resumindo bastante o processo. Vários outros detalhes técnicos foram levados em conta e implementados para a geração de mensagens.
Resultado
Após treinadas, as redes com a estratégia melhorada foram avaliadas negociando com os modelos mais simples (que aceitavam finalizar rápido) e também com humanos, que não sabiam se tratar de um computador do outro lado. Como esperado, a versão otimizada para negociar conseguiu tirar vantagem das redes neurais mais simples e, além disso, muitas vezes também saiu com mais pontos que os humanos.
Diga-se de passagem, a avaliação com humanos é bem semelhante ao teste de Turing. Neste caso, porém, as conversas são bem curtas, limitadas a um vocabulário específico e ainda assim alguns participantes perceberam que estavam falando com máquinas.
Negociador do Futuro?
Os resultados reportados são de fato empolgantes, mas, caindo no decepcionante mais uma vez, estamos longe de máquinas capazes de negociação super inteligente.
Há algumas limitações da IA. Uma delas é repetir a mesma proposta ou refraseá-la após receber uma recusa. Como resultado, muitas vezes as pessoas participantes não chegavam a um acordo com uma IA intransigente (após 10 mensagens de cada agente, se não houver acordo, o processo é finalizado). Além disso, o treinamento foi específico para esse cenário, embora a ideia geral possa ser aplicada para outras situações.
Por outro lado, a IA aprendeu uma estratégia interessante: fingir que tem interesse em algum dos itens, para depois abrir mão dele como se estivesse fazendo uma concessão para ganhar algo em troca. Segundo os pesquisadores, esse comportamento foi muito mais comum na IA do que nos humanos. Talvez ela não seja tão inofensiva assim :)
Para quem tiver curiosidade, o Facebook disponibilizou o código fonte de todo o experimento no Github.
Nenhum comentário:
Postar um comentário